
KNN算法用于回归预测及其代码实现

实际上,KNN算法是最早被使用的回归类的算法。在机器学习流行之前,在数据预测领域大都是使用K近邻算法来作回归预测。其原理与KNN算法用于分类是一致的:通过一种距离度量关系(通常为曼哈顿距离或欧几里得距离)寻找与待预测点相近的K个点,根据这K个点进行回归或是分类的预测。不同的是,分类任务中使用投票的方式,即待预测点的类别与K个点中数量最多的样本类别一致;在回归任务中,待预测点的标签由K个点标签的平均值决定。
今天想分享的是KNN算法用于回归预测的代码实现(非调用sk-learn库)。
下面是实现KNN算法的代码:
import distance # 导入距离度量函数的文件
from functools import partial # 使用偏函数方便解决距离及排序问题
class KnnRegression:
"""利用KNN算法实现回归任务"""
def __init__(self, n_neighbors=3, distance_algorithm='l2'):
self.n_neighbors = n_neighbors # 近邻的个数
self.distance_algorithm = distance_algorithm # 距离度量的方式
@property # 使用property装饰器进行包装方便偏函数的使用
def fun_distance(self):
if self.distance_algorithm == 'l2':
return distance.l2
else:
return distance.l1
def predict(self, data_sets, predict_points):
"""
参数data_sets表示现有数据的数据集,其为一个二维数组,每一行表示一条数据,最后一个数据项表示标签
参数predict_points表示待预测的数据集,其为一个二维数组,每一行表示一条数据,不包含标签
"""
predictions = []
for i in range(len(predict_points)):
fun = partial(self.fun_distance, b_factors=predict_points[i])
data_sets_sorted = sorted(data_sets, key=lambda x: fun(x[:-1]))
predictions.append(means(data_sets_sorted[:self.n_neighbors]))
return predictions
def means(neighbors):
"""求平均数作为预测值"""
count = 0
for neighbor in neighbors:
count += neighbor[-1]
return count / len(neighbors)下面是距离度量函数的代码,这里提供了l1、l2两种度量方式:
def l1(a_factors, b_factors):
"""l1范数,即曼哈顿距离"""
distance = 0
for i in range(len(a_factors)):
distance += abs(a_factors[i] - b_factors[i])
return distance
def l2(a_factors, b_factors):
"""l2范数,即欧几里得距离"""
distance = 0
for i in range(len(a_factors)):
distance += (a_factors[i] - b_factors[i]) ** 2
return distance ** 0.5下面对KNN算法进行测试,使用的数据是由函数 z=1 + sin(2*x+ 3*y) / (3.5 + sin(x- y))均匀生成,使用留出法提取20%的数据作为待预测点,使用r2作为评价指标。
import knn_regression
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from math import sin
def fun(X):
return (1 + sin(2*X[0] + 3*X[1])) / (3.5 + sin(X[0] - X[1]))
def r2(labels, predictions):
error = 0.0
means = sum(labels) / len(labels)
a, b = 0.0, 0.0
for label in labels:
b += (label - means) ** 2
for i in range(len(labels)):
a += (labels[i] - predictions[i]) ** 2
return 1 - a / b
factors = []
for i in range(100):
for j in range(100):
factors.append([-2 + 4 / 100 * i, -2 + 4 / 100 * j, fun([-2 + 4 / 100 * i, -2 + 4 / 100 * j])])
train, test = train_test_split(factors, test_size=0.2, random_state=0)
labels = [elem[-1] for elem in test]
test = [elem[:-1] for elem in test]
scores = []
for k in range(1, 21):
model = knn_regression.KnnRegression(k, 'l2')
predictions = model.predict(train, test)
scores.append(r2(labels, predictions))
plt.plot(scores)
plt.show()
选择距离度量方式为欧几里得距离,得到r2与k值选择图像如下:
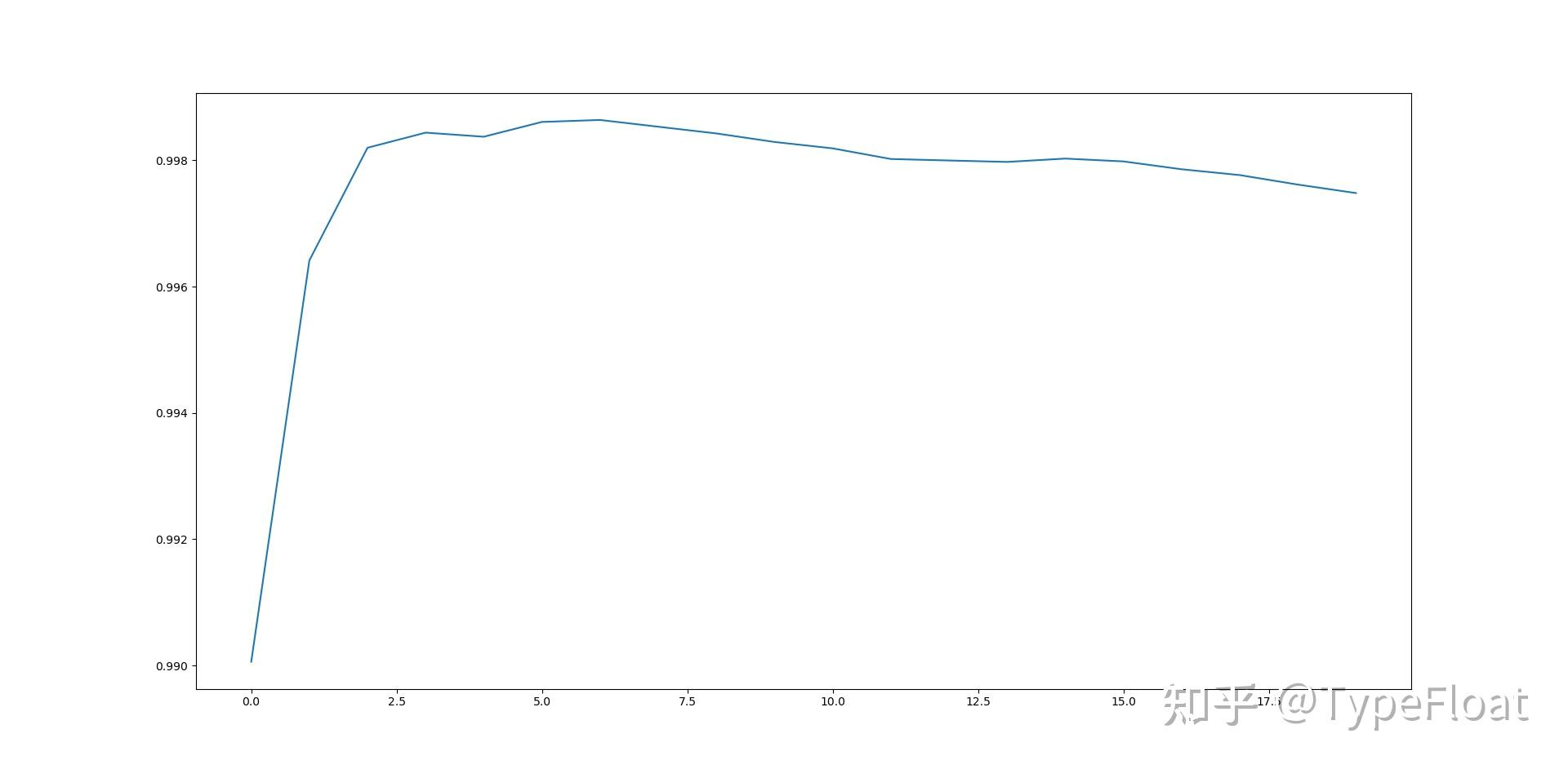

可以看到,当k=3时,r2值已经达到0.998左右,已经非常接近1,预测效果非常接近真实值。当k=6时达到r2的最大值。
因为KNN算法使用的是距离最近的几个值的平均值进行预测,因此只有当近邻足够接近待预测点时才可以达到最好的预测效果。假如在某个极端情况下,带预测点的真实标签为1.0,而通过距离度量得到的近邻标签分别为100.0、100.1、100.2,那此时的预测偏差就非常大了。换句话说,在回归任务中,要求数据集中样本点数量足够大,连续性较好才可以达到较好的预测效果。但当样本点数量足够大时,因为每次预测都需要计算带预测点与全部样本点的距离,又会出现计算量巨大的原因,导致运行时间特别长。
近来出现的如kd-tree、ball-tree等优化算法将运行时间长的缺点解决了。
文章被以下专栏收录
