
十分种读懂KNN

引言
机器学习的算法常常模拟人类的思考方式来对物体进行判断。在人类进行学习和理解世界的过程中,常常采用一种将相似物体分到同一类别的方式进行对事物的判断,也就是:“物以类聚,人以群分”的思维方式。机器学习中也有这样的分类算法。以下的例子可以帮助我们更好的解释这样的算法。
通过对于一些电影的画面内容的分析,我们发现,以下的几部电影有这样一些特点:
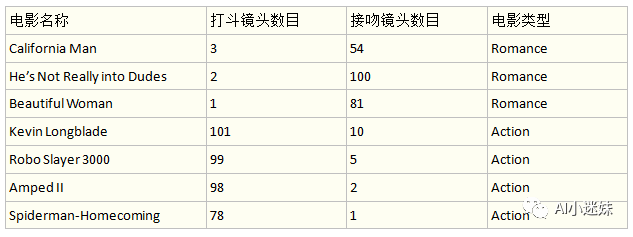

在一段视频类型的判断上,我们通过打斗镜头数目和接吻镜头数目来判断电影的类型,接吻多的是Romance类型的,而打斗多的是动作电影。当给出一段新的视频时,我们发现这一段视频中出现了75个接吻镜头,8个打斗镜头,那么我们如何判断新的视频的类型呢?
我们发现75和8这两个数字和上述表格仲的前三组数据很相近,而前三组数据都被归类为Romance类型的电影,所以新的视频也属于这样的类型。实际上,上述的问题是一个典型的邻近算法问题(或者说KNN,K-NearestNeighbor)。就是先用打斗次数和接吻次数作为电影的坐标,然后计算其他六部电影与未知电影之间的距离,取得前K个距离最近的电影,然后统计这k个距离最近的电影里,属于哪种类型的电影最多,比如Action最多,则说明未知的这部电影属于动作片类型。
在这样的算法中,我们首先要获得一些数据的特征和已知的他们的分类或者回归结果,面对新的数据的特征时,我们找到与新的数据特征最为相近,也就是特征的距离最小的K个已知数据,通过这K个数据的分类结果来判断新的数据的类型。当K个数据属于不同的类别的时候,我们就通过“少数服从多数”的方式来进行判断。下面我们就将介绍KNN邻近算法以及其中的实现细节。
什么是特征?
任何回归分类的判断都离不开对于特征的处理。一般情况下,我们的特征可以是连续的也可以是离散的。所谓连续的就是指在一定范围内,特征的数值可以是这个范围内的任何数字,比如温度、湿度、身高、体重。而离散的指的是特征的数值只能是一段数值中的某几个值,比如台阶的个数只能是整数,而不会出现是2.3这样的数字。在邻近算法在中,我们的所有特征都要是能通过数字来表达的值,不能是主观的判断,比如一般美,特别丑等等。
在KNN算法中,我们已知的数据的特征和需要被判断的特征都要是属于相同类别,特征的种类相同,数目相同。
在数学中,我们用坐标来表示点的位置,这个位置就可以认为是特征。而当特征的种类比较多时,我们采取一个数列来表示这种特征。当第i个人的身高(160cm)、体重(53kg)、视力(1.0)、年龄(17)、腰围(65cm)作为特征时,他的特征a可以表示为ai=(160, 53, 1, 17, 65)。这就是他的特征向量。
特征之间的距离
如何判断样本之间特征的相似程度呢?在直角坐标系中,我们用点与点之间直线距离表示点与点的相近程度,在邻近算法中,我们采取了相似的方式描述特征之间的相似程度。在一个直角坐标系中,点A(x1,y1)与点B(x2,y2)之间的距离常常可以计算为:
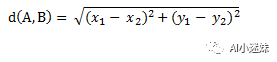
这个距离又叫做欧氏距离。
在邻近算法中,我们可以把每个样本看成是高纬度的空间中的点,而他们的相近程度也可以被点之间的距离来定义。我们假设此时我们有d维度的特征,也就是d维度的空间。那么样本下x,y相似度可以用欧氏距离表示为:
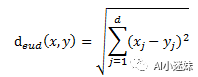
距离越近表示样本越相似,距离越大表示样本特征相差较大。
KNN邻近算法
KNN邻近算法的定义是指对一个D维空间的样本x,找到训练集样本空间中K个距离x最近的点,统计这K个距离最近的点的类别,找出个数对多的类别,将x归入该类别。
其实KNN是一种相当直观的算法,KNN通过比较一个未分类样本与已训练样本集的相似性,来确定该样本的类别。
KNN算法有以下的条件:
- 给出一个正整数K,作为最邻近的点的个数
- 给定一个已知类别的训练集
- 给定一个用来描述样本之间距离的标准
形象化的展示如下:
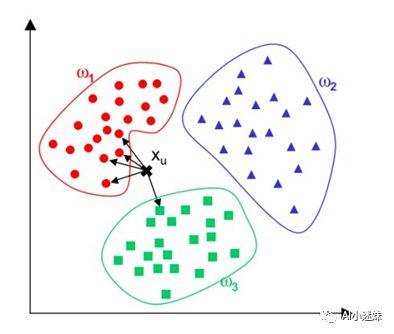
配图 1 通过KNN算法判断点的类别
我们需要判断Xu点的类别,属于红色、绿色还是蓝色类别,给出K=5的要求,找到欧氏距离定义下最为临近的5个点。此时发现这5个点有四个属于红色,一个属于绿色。说明在红色组出现的概率比较大,少数服从多数,那么心的点就属于红色类别。
K值的选择
KNN算法中,K的值是我们自己指定的,那么K的值应该如何进行选择呢?K值的选择又会对结果带来什么样的影响呢?如何根据不同的题目条件选择不同的K值呢?我们看这样一个例子:
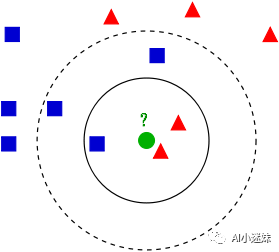
在图中,我们希望对绿色的圆形进行分类,判断这个圆形属于红色的三角形还是蓝色的方形。图片上的距离已经是距离绿色的点进行计算之后的距离。
配图 2 通过KNN算法判断点的类别
当我们认为K = 3 的时候,小圈里最近的点有三个,两个红色一个蓝色,那么红色的概率比较大,说明绿色的点属于红色类别。然而,如果我们认为K = 5,神奇的事情发生了,在虚线的圆里,有三个蓝色,两个红色的物体,那么按照少数服从多数的原则,绿色的小点应该属于蓝色类别。这个例子说明了,K的选择能够改变最终的分类结果。
事实上,k值选择过小,得到的近邻数过少,会降低分类精度,同时也会放大噪声数据的干扰;而如果k值选择过大,并且待分类样本属于训练集中包含数据数较少的类,那么在选择k个近邻的时候,实际上并不相似的数据亦被包含进来,造成噪声增加而导致分类效果的降低。
在实际的使用中,K值的选择通常小于训练样本数目的平方根。还常常对不同的K值进行多次实验,找到最为合适的K值。
而在上图中我们又意识到,距离样本相对近的点和在K值范围内距离样本相对远的点实际上可能对样本的分类有不同的意义。距离近的点理应在分类结果上受到偏向和有待。所以在实际计算中,当确定了K值范围内的点后,我们不仅仅采取“少数服从多数”的思想,而是让距离样本近的点拥有更大的话语权,加重他们的权重。
拓展阅读:K值的选择
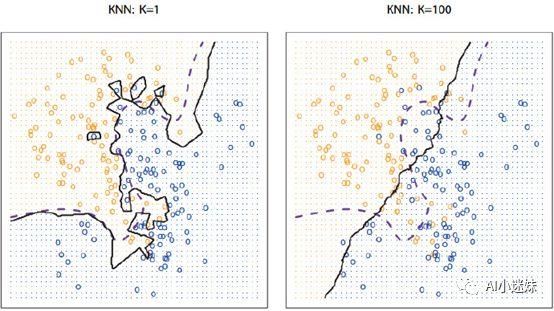

配图 3 K值对于分类结果的影响
在上图中,我们想要把黄色和蓝色的样本进行区分,图上的每一点都是已知的训练数据,紫色的线描述了实际上的真是分类曲线。黑色的线描述了使用KNN算法时采用不同的K值进行计算后得到的分类曲线。我们可以发现,K越小,分类边界曲线越光滑,偏差越小,方差越大;K越大,分类边界曲线越平坦,偏差越大,方差越小。当k值比较小的时候,容易发现“过拟合”现象,即拟合的结果和给出的例子关系很大,而K值过大,常常出现“欠拟合”现象,也就是说拟合的不够精准。关于“过拟合”和“欠拟合”的问题我们会在其他算法进一步讨论。
KNN算法优劣
优势:
- KNN算法与人类日常思考模式很相近,不需要估计参数,也不会生成最终的分类器。
- 适合对稀有事件进行分类。较小数据量的快速分类常常使用KNN算法。
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签)。在这一类问题上,KNN算法要优于很多其他的机器学习算法。
劣势
- KNN算法是一种懒惰算法,进行分类时由于要计算每个样本之间的距离,计算开销很大,运行比较慢。当数据量非常大时,不适合用KNN算法。
- 当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。在极端情况下,如果某一类别的样本数目甚至小于K,那么最终的分类结果势必要收到很大的影响。
- 分类结果完全以来于训练样本,不能给出分类规则。
KNN算法流程
- 准备数据,对数据进行预处理
- 选用合适的数据结构存储训练数据和测试数据
- 设定参数,如k,选择距离评判方式
- 维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练数据。随机从训练数据中选取k个数据作为初始的最近邻样本,分别计算测试数据到这k个样本的距离,将训练样本标号和距离存入优先级队列
- 遍历训练数据集,计算当前训练数据与测试数据的距离,将所得距离L 与优先级队列中的最大距离Lmax
- 进行比较。若L>=Lmax,则舍弃该数据,遍历下一个数据。若L < Lmax,删除优先级队列中最大距离的数据,将当前训练数据存入优先级队列。
- 遍历完毕,计算优先级队列中k 个数据的多数类,并将其作为测试数据的类别。
- 测试数据集测试完毕后计算误差率,继续设定不同的k 值重新进行训练,最后取误差率最小的k 值。
学会使用Scikit-Learn中决策树工具
【问题描述】
你在一家互联网企业从事数据挖掘的职位,你的朋友在同一家互联网公司的人力资源部工作,经常要筛选各类简历。她最近在忙于找到合适的软件开发工程师人选,可是简历很多,她想通过几个标准对候选人进行分类。在从前的招聘过程中,曾经留下了之前候选人的资料和他们面试的评级,这位HR小姐姐希望在输入一些特征之后,直接对评级进行预测,减少工作量。特征分别是“每半年写程序行数”,“在github上提交开源代码的项目数”和“每个月看专业书籍的数量”。HR小姐姐将这些候选人分类为“牛逼程序员”(1),“一般程序员”(2)和“有待提高的程序员”(3)。这些数据的一部分例子如下,其他数据保存在txt文档中。
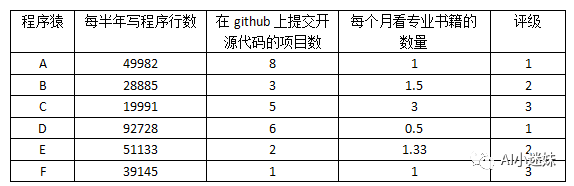

【应聘者条件与应聘结果】
【解题思路】
1) 数据预处理:
我们得将txt文本中提供的数据放到矩阵或矢量中进行存储,然后还需要将数据进行归一化。
- 首先将数据从txt转化为矩阵进行存储
#函数名:file2matrix
#输入:文件名
#输出:returnMat为txt文本数据的前三列构成的二维数组
# classLabelVector为txt文本数据第四列的分类信息的一维矢量
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
- 将数据进行归一化
为什么要进行数据归一化?分析下数据可以看出,代码数量相对于其他两个特征的数据来说通常要大的多,如果不进行数据归一化,那么在计算距离的时候飞行距离对结果的影响占绝对主导性,这显然是不合理的,所以需要进行数据归一化,归一化的python代码如下所示:
#函数名:autoNorm
#输入:dataSet为原始数据二维数组
#输出:normDataSet归一化之后的二维数组,ranges为每一列最大值减去最小值的范围,minVals为每一列的最小值。
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
2)测试算法
通常来说,我们使用数据的90%作为训练数据,10%的数据作为测试数据。测试的指标为出错率,当预测的分类和实际的分类结果不一致时,记录一个错误,错误的总数/测试的样本数即为出错率。
#函数名:workingClassTest
#输入:无
#输出:无,但是会打印出错个数及错误率。
def workingClassTest():
hoRatio = 0.50 #hold out 10%
workingDataMat,workingLabels = file2matrix('workingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(workingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],workingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, workingLabels[i])
if (classifierResult != workingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
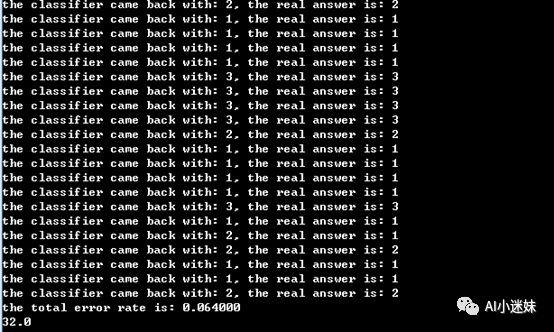
结果如下, 错误率为6.4%

3)应用算法:
当错误率达到满意时,我们对算法进行使用。
def classifyPerson():
resultList = ['excellent','so so','not good']
github = float(raw_input("githubproject:"))
codelines = float(raw_input("linesofcode"))
bookNum = float(raw_input("reading books per month:"))
workingDataMat, workingLabels = file2matrix("workingTestSet2.txt")
normMat, ranges, minVals = autoNorm(workingDataMat)
inArray = array([codelines, github, bookNum])
classifyResult = classify0((inArray - minVals)/ranges, normMat, workingLabels, 3)
print "prediction result is: ", resultList[classifyResult - 1]
运行结果knn.classifyPerson() 输入三个指标,就可以帮助HR小姐姐减小工作量啦。
想学习了解人工智能知识的小伙伴们,请关注:
http://weixin.qq.com/r/KSoBGQ3EulDFrUl69387 (二维码自动识别)
文章被以下专栏收录
