网站最大并发数以及服务器配置预估
标签: 高并发
一.评测网站常用的一些术语:
以www.qq.com为例子,我们可以在 站长之家输入www.qq.com获得结果:
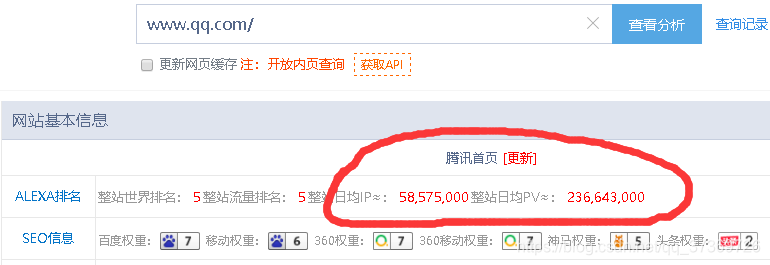
日均ip:每天有多少个ip访问qq,我们可以看到qq是接近六千万,然后用的人远不止这些,因为如果在一个局域网里面访问使用qq的话,局域网最终有几个出个ip,就是多少个ip。
日均pv:我们一个人用一个ip去访问qq,然后在里面点了几个页面,这个就是PV。也就是说pv/ip就是每个ip访问的页面数量,通常这个数越大就说明你的网站越受欢迎,而不是点一下就走了。
还有几个术语:
UV:这个是多少个用户,前面说ip是出口ip,那么有多少人就是这个UV了。
DAU:这个和UV有些类似,但是这个一般用在移动端APP中,日活跃用户数。
MAU:移动端APP月活跃用户数。
二.网站最大并发数
并发数:
并发用户数量,有两种常见的错误观点。一种错误观点是把并发用户数量理解为使用系统的全部用户的数量,理由是这些用户可能同时使用系统;还有一种比较接近正确的观点是把用户在线数量理解为并发用户数量。实际上,在线用户不一定会和其他用户发生并发,例如正在浏览网页的用户,对服务器是没有任何影响的。但是,用户在线数量是统计并发用户数量的主要依据之一。
并发主要是针对服务器而言,是否并发的关键是看用户操作是否对服务器产生了影响。因此,并发用户数量的正确理解为:在同一时刻与服务器进行了交互的在线用户数量。这些用户的最大特征是和服务器产生了交互,这种交互既可以是单向的传输数据,也可以是双向的传送数据。
测试并发量:
使用apache的ab命令,没有的话先安装一下httpd(安装只会占磁盘空间,不启动对内存不会有什么影响):
yum install -y httpd
使用ab命令测试www.qq.com,你也可以测试自己的网站,比如说我自己的网站127.0.0.1。
# -c指定并发数,-n指定请求数量
ab -c 100 -n 1000 http://127.0.0.1/index.html
查看结果:
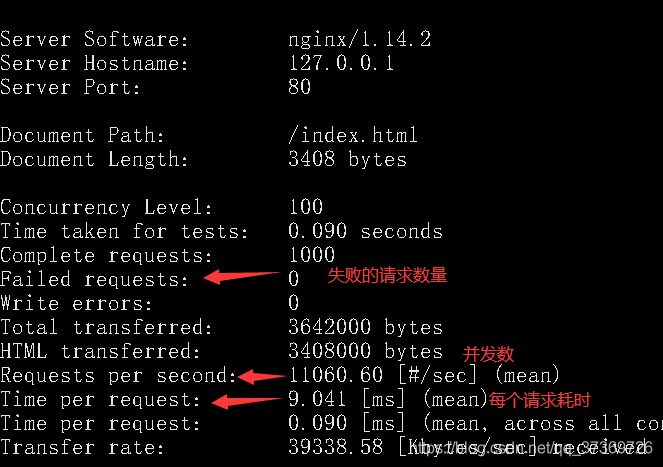
上面可以看出我自己的1核2G内存的云服务器是1万1的并发量。我的web就只有一个静态页面,没有动态请求,理论上nginx的静态页面支持3万的高并发。
然而这并不能说明什么,生产环境中不可能没有动态请求,还有和数据库的交互以及带宽。犹如一个银行里面,大厅的人数多少还不能说明处理能力的快慢。
吞吐量:
与高并发相关的一个参数叫做吞吐量,这个就想是银行柜台窗口。吞吐量的多少决定了真正并发数量的多少。哪怕我服务器写的并发很高,也会被限制,有时候并发太高了,吞吐量反而会变低,因为太“拥挤”了。按理来说,cpu核数多少就是多少个窗口,但是呢,吞吐量不是这样的,这样太浪费cpu资源了。假如银行柜台办业务中途需要填个表,现实中可能是等你填完,然后继续。但是cpu不是,在一个请求处理等待返回结果的时候,cpu已经开始下一个了,等返回了值再处理一下。这样下来,每秒钟能处理多少请求呢,就是吞吐量。下面说一下服务器预估,结合起来说并发和吞吐量。
三.服务器配置预估
例如:8核至强E5,8g内存。
按照经验来说,跑纯php页面,跑300(吞吐量)已经很优秀了,150左右响应时间已经明显变慢了。
这里说的并发包括静态和动态,一般来说一个网页静态内容占80%左右,
还有网站的80%的pv是在20%(24小时算)的时间内完成的
计算它一天的请求数的话(吞吐量150算):
240.23600*150/0.8=340万
请注意是请求数,一个html页面包括各种图片,js,css资源,这些都是请求。
一个网页有动态资源和静态资源,如果按2:8来算的话,
pv=请求书/5=68万。
上面的一些比例可以根据自己的服务器换算。
智能推荐

实现并发服务器
实验要求 修改远程控制服务器代码,使得服务器同时能够向多个用户提供服务。消除僵尸进程,收回所有子进程资源。 实验环境 Red Hat 9 代码 server.c tcpclient.c tcpserver.c 运行结果 启动服务器 启动三个客户端分别输入测试命令ls、whoami、pwd,服务端执行命令后将结果回显在客户端。 客户端向服务端发送命令,服务端执行 输入命令netstat -anp |...
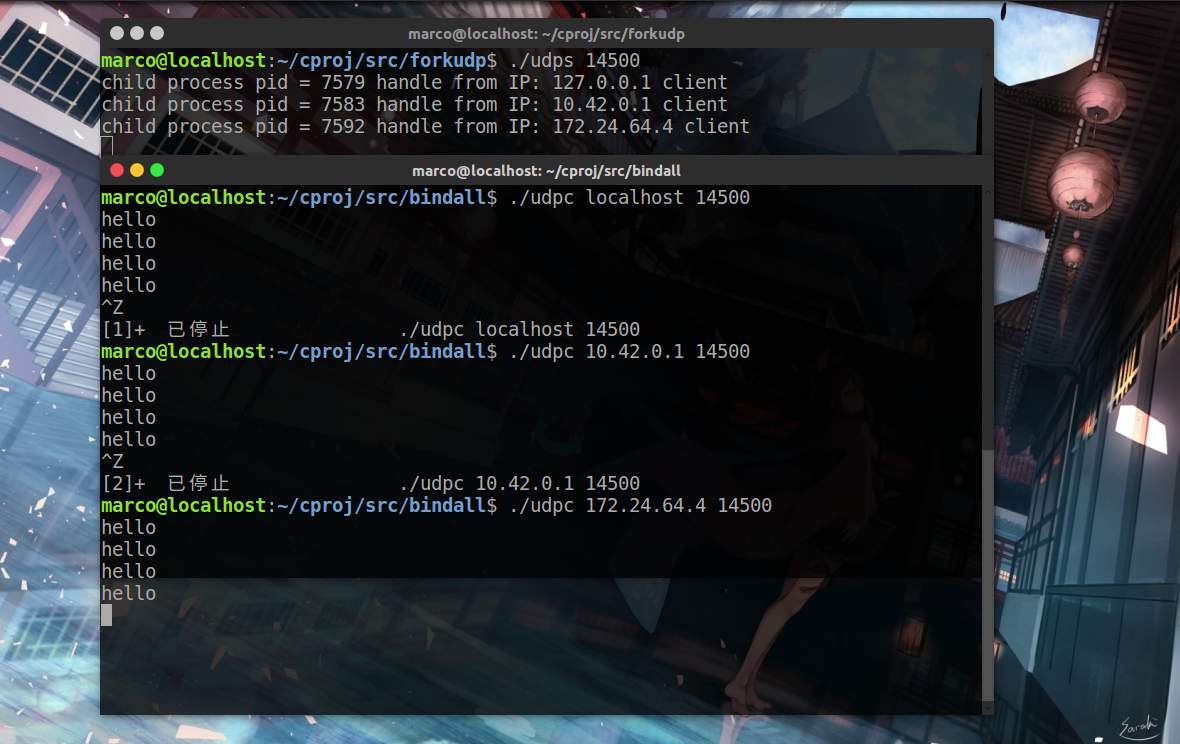
并发UDP服务器
服务器端代码如果采用fork写时复制(Copy on Write)技术,代码还可以更简洁一点 服务端代码: 客户端代码:...
NTP时间服务器配置以及错误的总结
NTP全称是Network Time Protocol,也就是互联网时间协议,说到时间,就谈谈时间的一些概念吧; 时区 按照常识来说,一天被划分24小时,近似球体的地球是360度,所以使用经纬度为坐标,将全球划分为24个时区,每个时区是15度; 东八区 格林尼治时间为世界标准时间,又因为,东半球(格林尼治以东)的时间比较早,中国的经度在120E,是位于第八个时区,这里的中国表示北京或者上海,因为横...

盒模型(IE,W3C)
W3C盒模型 IE盒模型 从上图可以看到 ie 盒子模型的范围也包括 margin、border、padding、content,和标准 w3c 盒子模型不同的是: ie 盒子模型的 content 部分包含了 border 和 pading。 两者的不同体现在width和height上 IE:width=content+padding+border W3C...
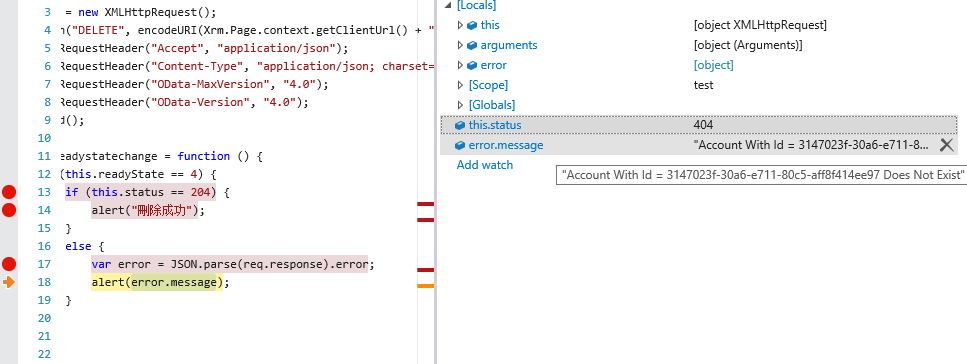
Dynamic CRM 2016使用WEB API删除记录(js)
删除实体记录,代码如下 删除使用DELETE (1)记录存在返回响应内容如下: (2)记录不存在返回如下:...
猜你喜欢

马拉车算法(Manacher's Algorithm)
这是悦乐书的第343次更新,第367篇原创 Manacher’s Algorithm,中文名叫马拉车算法,是一位名叫Manacher的人在1975年提出的一种算法,解决的问题是求最长回文子串,神奇之处在于将算法的时间复杂度精进到了O(N),下面我们来详细介绍下这个算法的思路。 01 算法由来 在求解最长回文子串的问题时,一般的思路是以当前字符为中心,向其左右两边扩展寻找回文,但是这种解...

HTML学习笔记--第一天
1界面基本结构 HTML存在有版本差异 HTML5的头部 其他版本 页面标签 meta标签 META元素通常用于指定网页的描述,关键词,文件的最后修改时间,作者及其他元数据。 元数据可以被使用浏览器(如何显示内容或重新加载页面),搜索引擎(关键词),或其他 Web 服务调用。 <h1>----<h6>标签 定义了六个不同级别的标题 <p></p>标签...

springcloud之熔断器hystrix及服务监控Dashboard
文章目录 一、服务雪崩效应 二、服务熔断服务降级 三、hystrix默认超时时间设置 四、hystrix服务监控dashboard 一、服务雪崩效应 当一个请求依赖多个服务的时候: 正常情况下的访问(图解) 但是,当请求的服务中出现无法访问、异常、超时等问题时(图中的I),那么用户的请求将会被阻塞。 如果多个用户的请求中,都存在无法访问的服务,那么他们都将陷入阻塞的状态中。 Hystrix的引入,...

使用for循环遍历文件、使用while循环遍历文件
使用for循环遍历文件 1、打开文件读 打开文件,从头到尾读完后,再执行read()就没有了 关闭后就不能读 readlines()和readline()区别: readline() :一行一行读取,返回字符串,当指针到文件末尾后,返回空 readlines():整个内容都输出,再输入,返回空 fd.next(): 和readline() 差不多,不过读完最后一行,返回报错 2、打开文件写 f =...

带权并查集_How Many Answers Are Wrong
这道题有点巧妙~ 大致题意:给定一个数组,每次给出l,r,value表示区间 [ l , r ] 的总和为value,但每次给出的value可能和前面的答案有冲突,求冲突次数。 举例:好比如前面给出了[1,10]的和为100、[1,7]的和为60,那么自然就可以确定[8,10]的和为100-60=40,但题目术输出却给出[8,10]的和为80,那么就和前面的答案冲突了。 这道题的突破点在于,可以以...